-
Data Analysis with Python - Module Evaluation & Learning ObjectviesData Science 2022. 8. 13. 18:16
- In sample evaluation의 단점: it does not tell us how well the trained model can be used to predict new data
- Solution? Separate the data to two dataset (Training set, Testing set)
- First we build our data with training set, then use testing set to assess the our model

- Training data를 많이 넣을수록 Generalization error 이 발생할 가능성이 높아짐 / 때문에 여러 training data & testing data set를 넣어서 이를 보완한다. 이를 Cross validation이라 함

- 코드:
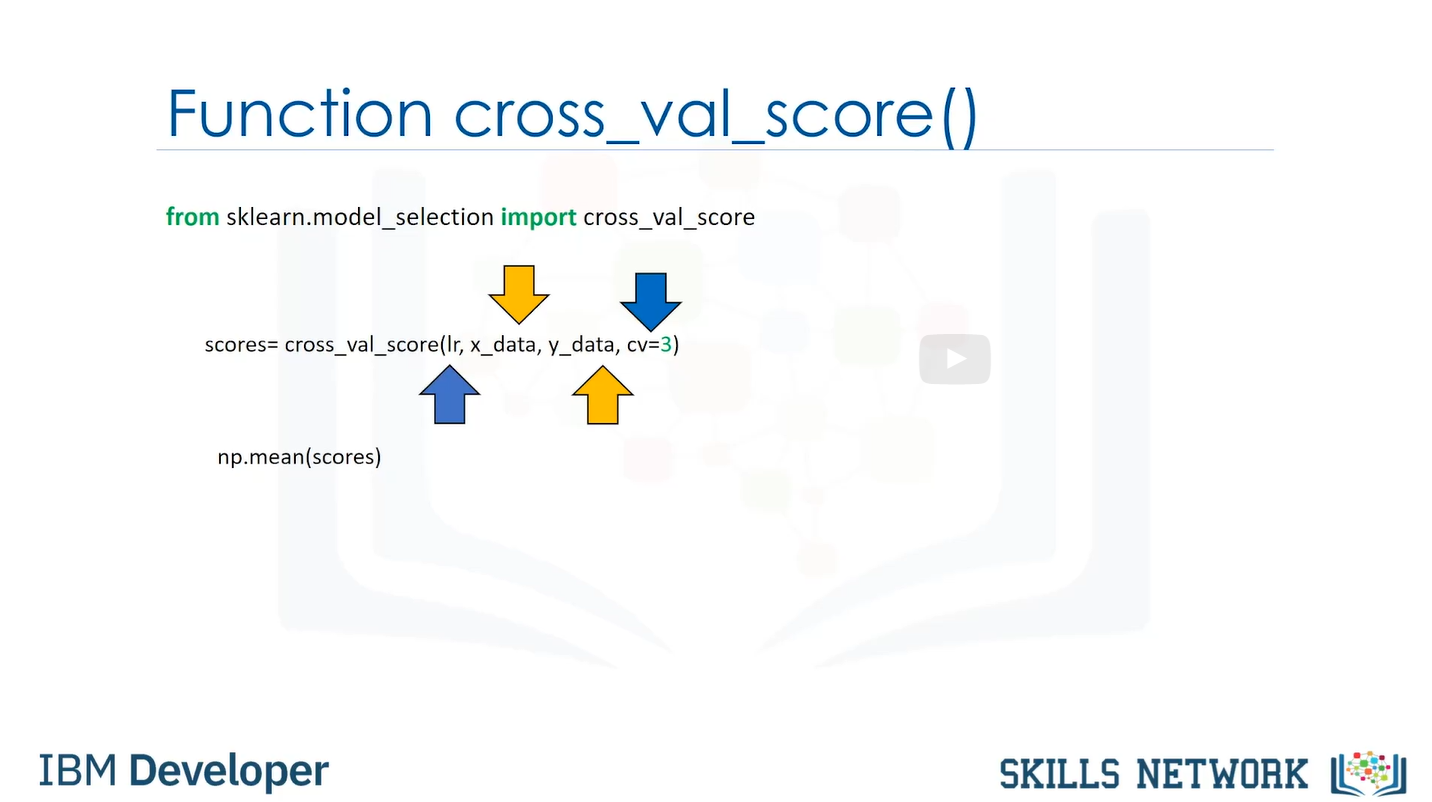
- Ir = Linear regression, cv = 파티션조합)의 개수
- 그렇다면 actual predicted values를 구하고 싶을 경우에는?
function cross_val_predict()- Order(차수)와 Error MSE와의 관계: order가 너무 높아지면 overfitting 이 발생하고, 너무 낮아지면 underfitting 이 발생한다

- How to calculate different R-squared values? ↓
Rsqu_test = [] # create an empty list to store the value order = [1,2,3,4] # create a list containing different polynomial orders (1,2,3,4차수) for n in order: # iterate through the list using a loop pr = PolynomialFeatures(degree = n) x_train_pr = pr.fit_transform(x_train[['horsepower']]) x_test_pr = pr.fit_transform(x_test[['horsepower']]) lr.fit(x_train_pr, y_train) Rsqu_test.append(lr.score(x_test_pr, y_test)- Ridge regression: used to prevent overfitting
- Ridge regression을 만들기 위해서는 alpha를 지정해주어야 함
- alpha가 0인경우 -> underfit
- alpha가 10인경우 -> 마찬가지로 underfit
- alpha 0.01정도가 좋다 (cross validation을 사용해 적절한 값을 찾아야 함)

- 아래는 코드

- 과정:
- 가장 높은 R^2값을 가진 alpha를 보통 선택한다. MSE도 고려해서 정할 수 있다.(가장 낮은 MSE값)
- Grid search: allows us to scan through multiple free parameters with few lines of code
- 코드:
-

- Three different sets in grid search: Training, Validation, Test
- 코드는 아래와 같다 ↓
from sklearn.linear_model import ridge from sklearn.model_selection import GridSearchCV # import ridge, GridSearchCV# The dictionary of parameter values
prameters1 = [{'alpha': [0.001, 0.1, 1, 10, 100, 1000, 10000, 100000, 1000000]}]# Create a ridge regression object
RR = Ridge()# Create a GridSearchCV object
Grid1 = GridSearchCV(RR, parameters1, cv=4)# Fit the object
Grid1.fit(x_data[['horsepower', 'curb-weight', 'engine-size', 'highway-mpg']], y_data)# Find the best values for the free parameters
Grid1.best_estimator_# Get the mean score
scores = Grid1.cv_results_ scores['mean_test_score']'Data Science' 카테고리의 다른 글
Machine Learning with Python - Intro (0) 2022.08.18 goodFeaturesToTrack method 이용해 코너 검출시 Can't parse 'center'. Sequence item with index 0 has a wrong type 에러 (0) 2022.08.14 Data Analysis with Python - Model Development (0) 2022.08.13 Data Analysis with Python - Exploratory Data Analysis (0) 2022.08.13 Data Analysis with Python - Data Wrangling (0) 2022.08.13